In ESP experiments, the stacking effect occurs when several participants respond to the same target, making trials statistically dependent. This article explains why such designs can distort significance testing, reviews older correction methods, and recommends simulation or permutation approaches that better handle shared targets and response tendencies.
- The stacking effect arises when multiple ESP responses are made to the same target, making trials non-independent.
- Ordinary binomial analysis may overstate significance when response tendencies are shared across participants.
- Simulation and permutation methods can adjust for stacking effects without discarding information from the data.
Contents
The Stacking Effect
The stacking effect occurs in ESP research when multiple participants guess or respond to the same target rather than each participant having his or her own randomly selected target. Multiple responses to one target change the statistical properties of the data analysis and can tend to make the outcome of an experiment less significant than if each participant has a randomly selected target. Multiple responses for one target may be useful or necessary in certain situations but should be analysed with appropriate methods.
Avoiding multiple responses for a target is preferable whenever possible because participants’ response tendencies can reduce the ability to detect ESP compared to experiments with a separate random target for each response. Also, data analysis is much simpler with a separate target for each response. Experimental designs with multiple responses for one target are seldom needed with the current wide use of automated data collection systems. However, this can result in researchers being unfamiliar with the statistical issues and methods for evaluating data with stacking effects when the need arises. A lack of knowledge about the stacking effect can result in researchers using inappropriate analysis methods or unnecessarily rejecting any experiment with multiple responses for one target.
The potential differences between experimental designs with and without stacking effects can be seen by examining a hypothetical case. In this hypothetical experiment, participants are tested in groups of three. Each participant does one trial that is a guess or response about a hidden target. The target can be either T1 or T2 with a probability of 1/2 for each possibility. In this hypothetical case, a group of participants talked with two people who had previously completed an experimental session and both persons said they received target T1. This inspired the three participants to decide they will all make response T1 for their trials.
Figure 1 shows a diagram of the case when all three participants have the same target (stacking effect) and the case when each participant has a separate randomly generated independent target, designated binomial analysis because that is the traditional method of analysis.
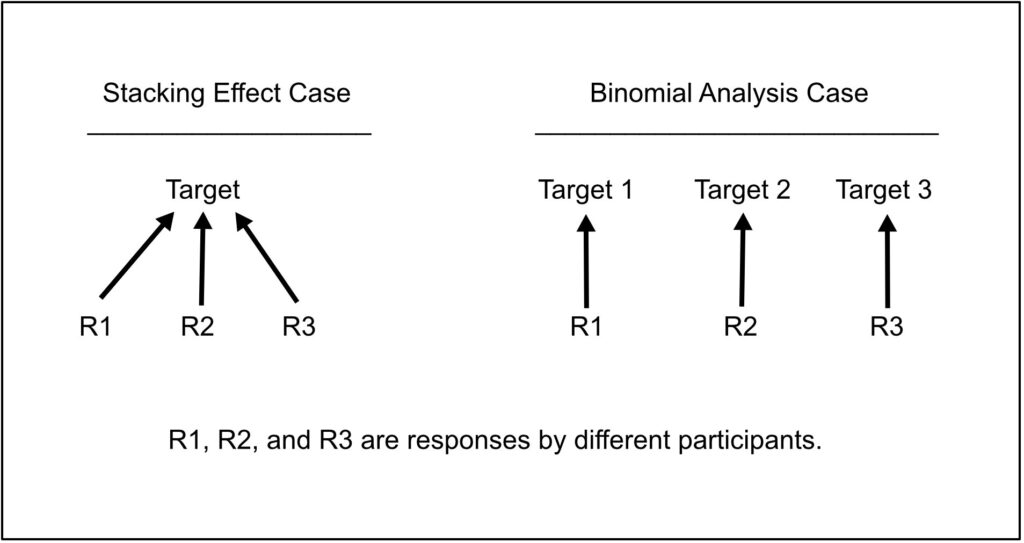
Figure 1. Responses and targets for cases with and without stacking effects.
Table 1 shows the various possible outcomes and associated probabilities for the three trials with the usual null model or null hypothesis that ESP does not occur and that the outcome is due to chance variability. When all three participants make the same response for one target, they will all have the same outcome, either a hit or a miss. The probability for three hits is 1/2 and the probability for three misses is 1/2. If all three participants make the same response, two hits or one hit in the three trials cannot occur.
For comparison, when each of the participants has a separate independent target (binomial analysis case), the probability that all three participants obtain a hit is 1/8. One or two hits are most likely in the three trials.
| N Hits | Stacking Effect Case probability if no ESP | Binomial Analysis Case probability if no ESP |
| 3 | 1/2 | 1/8 |
| 2 | 0 | 3/8 |
| 1 | 0 | 3/8 |
| 0 | 1/2 | 1/8 |
Table 1. Possible outcomes with and without stacking effects when three participants all make the same response for Phit = 1/2.
These two cases clearly have very different properties but note that the long-term expected proportion of hits by chance in both cases is 1/2. However, the stacking effect produces a much greater probability of an extreme outcome occurring by chance. This reduces the ability to detect an ESP effect. In statistical terminology, the stacking effect makes trials not independent, which can produce a larger variance than with the binomial model and make the outcome less significant than with the usual binomial analysis. Stacking effects apply to both forced-choice and free-response experiments.
This extreme case of all participants making the same response is unlikely to occur in practice, but the tendency to make similar responses is applicable – and usually to an unknown degree due to factors like common guessing habits and shared influences from recent events. However, if a separate target is randomly generated for each response (binomial analysis case), the participants’ response tendencies do not require special analyses that can reduce the ability to detect ESP.
Analysis of Data with Stacking Effects
When multiple responses for a target is the best or only option for an experiment, statistical analyses can be applied that adjust for stacking effects. The need for special analysis was recognized by the 1940s. Greville1Greville (1944). developed a method to adjust for the stacking effect in 1944. Pratt2Pratt (1954). presented the calculations in a form accessible to non-statisticians in 1954. Thouless and Brier3Thouless & Brier (1970). noted that the Greville method in practice usually produced less significant results than a binomial analysis. Burdick and Kelly4Burdick & Kelly (1977). endorsed and explicated Greville’s method but presented the calculations in matrix notation that is primarily accessible to statisticians.
Like all statistical methods from the early twentieth century, the Greville method was based on mathematical models that have assumptions and approximations that work well in some cases but not in others.5Burdick & Kelly (1977); Scott (1972), in reference to Pratt (1969). Extensive experience is needed with such models to develop a working understanding of their limitations. The needed extensive experience has not been obtained with the Greville method.
However, with current computer technology, simulations provide a more theoretically correct and easier-to-understand analysis strategy. These simulations are based on the same logic as the Greville method but apply computer power rather than mathematical approximations that limit the range of application.
An entire experiment is simulated thousands of times, typically 10,000 to 50,000 times. Each simulation generates random targets using the same target pool and randomization steps as the original experiment, including whether the targets are balanced or unbalanced. Thus, each simulation has targets that could have occurred in the original experiment if the randomization had turned out differently. These simulations are in the general category known as resampling methods for data analysis.
The new random targets in the simulations are evaluated against the responses obtained in the original experiment. Under the null model that ESP does not occur, the responses are assumed to be unrelated to the targets and the same response on a trial would have been made if the target had been different. A score such as overall hit rate for an experiment is calculated for each simulation. If the null model does not apply and the responses are related to the targets, the originally obtained score will be higher than for most of the simulated outcomes. The p-value for the experiment is the proportion of simulations that had a score as high or higher than the score observed in the original experiment.
As usual with traditional frequentist statistical methods, if the observed outcome would be rare if the null model is true (often p-value < .05), an inference is made that the null model does not apply and that an effect occurred. Whether the effect can be attributed to ESP will depend on other aspects of the study design.
The p-values from the simulations adapt to any response tendencies among the multiple responses to one target. For free-response experiments, multiple judges can be treated as multiple responses to a target and the same strategy applied. Also, the strategy can be used with rating scales (eg, 1 to 100) that indicate the degree of correspondence between the target and response but have unpredictable properties that do not fit mathematical models. These simulations of the experiment are widely applicable and are an optimal analysis for virtually any psi experiment with randomization.
A refinement of this strategy that is a little more conservative is to use the same targets that occurred in the original experiment rather than generate completely new targets for each simulation. The targets from the experiment are randomly permutated among the responses for each simulation. This adjusts for any imbalance in the targets that may have occurred by chance when the original targets were randomly selected. The value of this refinement can be debated.
Evaluating the Difference between Conditions
The same process can be used to evaluate the difference between two conditions or groups. Simulations would be done with new random targets that could have occurred in the original experiment. The hit rate or some other measure would be calculated for each condition and the difference determined. The p-value for the evaluation of the difference between conditions would be the proportion of simulated differences that were as large or larger than the originally observed difference. This analysis has the null hypothesis that no ESP occurred in the experiment. A significant p-value is evidence that ESP manifested as a difference between conditions.
A different analysis strategy could be used that does not start with the assumption that no ESP occurred in the experiment. This strategy starts with the assumption or null model that any effects in the experiment were the same in the two conditions. If that is true, any independent trial that occurred in one condition could also have occurred in the other condition. The simulations randomly permutate the observed trials among the two conditions and calculate the difference. This uses the observed data without generating new possible targets. As usual, a p-value is generated by the proportion of simulations that have a difference as large or larger than the observed different. The independent trials that are permutated are each randomly generated target and all the responses made to that target. The target and responses are permutated together as a fixed block.
Majority-Vote Analysis
A majority-vote analysis is another option for evaluating multiple responses to each target.6Thouless & Brier (1970). For each target, the response that occurred most frequently is treated as a single response and the other responses are ignored. The statistical analysis is based on the single response for each target and the usual binomial analysis is applicable.
However, a majority-vote analysis is generally less sensitive (has lower power) than simulations or the Greville method.7Burdick & Kelly (1977). When the most frequent response is determined for a target, information about the magnitude of the majority and near misses is discarded. This lost information would be expected to reduce the sensitivity of the analysis compared to simulations and the Greville method that do not discard information. However, a majority-vote analysis is much easier than simulations or the Greville method and may be useful if a large amount of data is available.
James E Kennedy
Works Cited
Burdick, D.S., & Kelly, E.F. (1977). Statistical methods in parapsychological research. In Handbook of Parapsychology, ed. by B.B. Woman, 81-130. New York: Van Nostrand Reinhold.
Greville, T.N.E. (1944). On multiple matching with one variable deck. [Download PDF.] Annals of Mathematical Statistics 15, 432-34.
Pratt, J.G. (1954). The variance for multiple-calling ESP data. [Full text.] Journal of Parapsychology 18, 37-40.
Pratt, J.G. (1969). On the Evaluation of Verbal Material in Parapsychology. [Full text.] Parapsychology Foundation Monograph 10. New York: Parapsychology Foundation.
Scott, C. (1972). On the evaluation of verbal material in parapsychology: A discussion of Dr. Pratt’s monograph. Journal of the Society for Psychical Research 46, 79-90.
Thouless, R.H., & Brier, R.M. (1970). The stacking effect and methods of correcting for it. [Full text.] Journal of Parapsychology 34, 124-28.